
近日,我院可视媒体与大数据实验室传来喜讯。在 2026 年 2 月 21 日公布的 IEEE/CVF 计算机视觉与模式识别会议(CVPR 2026)论文录用结果中,分别由二年级硕士研究生林宣佐和三年级研究生方洪伟作为第一作者的两项研究成果成功入选。CVPR 是国际计算机视觉与人工智能领域最具影响力的学术会议之一,被中国计算机学会评定为 A 类会议。本届会议共收到 16092 篇有效投稿,最终录用 4090 篇,录用率约为 25.42%。会议将于 2026 年 6 月在美国丹佛举行,论文作者届时将在大会上汇报相关研究成果。
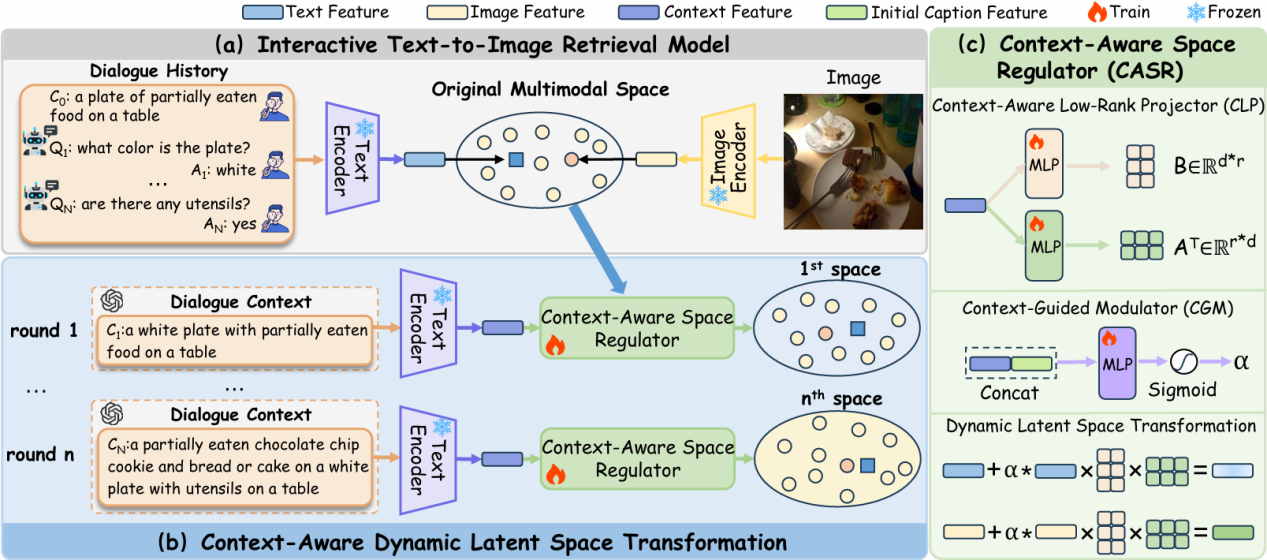
论文标题:CAST: Context-Aware Dynamic Latent Space Transformation for Interactive Text-to-Image Retrieval
论文作者:林宣佐1,张敏2,刘岱宗3,左智文1,杨勋4,林昶廷5,王勋1,董建锋1
完成单位:1. 浙江工商大学 2. 华东师范大学 3. 武汉大学 4. 中国科学技术大学5. 浙江大学
论文简介:
在交互式图像检索与人机对话系统快速发展的背景下,用户不再满足于单次输入查询,而是期望通过多轮自然语言交互动态表达。交互式文本到图像检索任务应运而生,旨在通过对话历史理解用户的渐进式需求,从而实现更精准、更贴合用户预期的视觉内容检索。
然而,现有方法通常在一个固定的多模态嵌入空间中进行跨模态匹配,难以捕捉用户意图在多轮对话中的动态演化,导致语义模糊和检索精度受限。针对这一瓶颈,本文提出了一种轻量级且即插即用的动态潜在空间变换框架—CAST(Context-Aware Latent Space Transformation)。CAST的核心在于其上下文感知空间调节模块CASR,由两个协同组件构成:一是上下文感知低秩投影器CLP,通过低秩分解学习与对话语义相适应的投影方向;二是上下文引导调制器CGM,根据语义变化动态调节变换强度。该设计使得CAST能够根据用户的搜索意图实时重塑文本与图像特征空间,实现细粒度、可适应的语义对齐。
与现有方法相比,CAST几乎不引入额外参数和计算开销,可无缝集成至多种I-TIR框架中。大量实验表明,CAST在VisDial数据集上显著超越现有方法,尤其在多轮交互后期性能提升更为明显,展现了其在交互式检索任务中的高效性与泛化能力。项目代码即将开源:https://github.com/HuiGuanLab/CAST
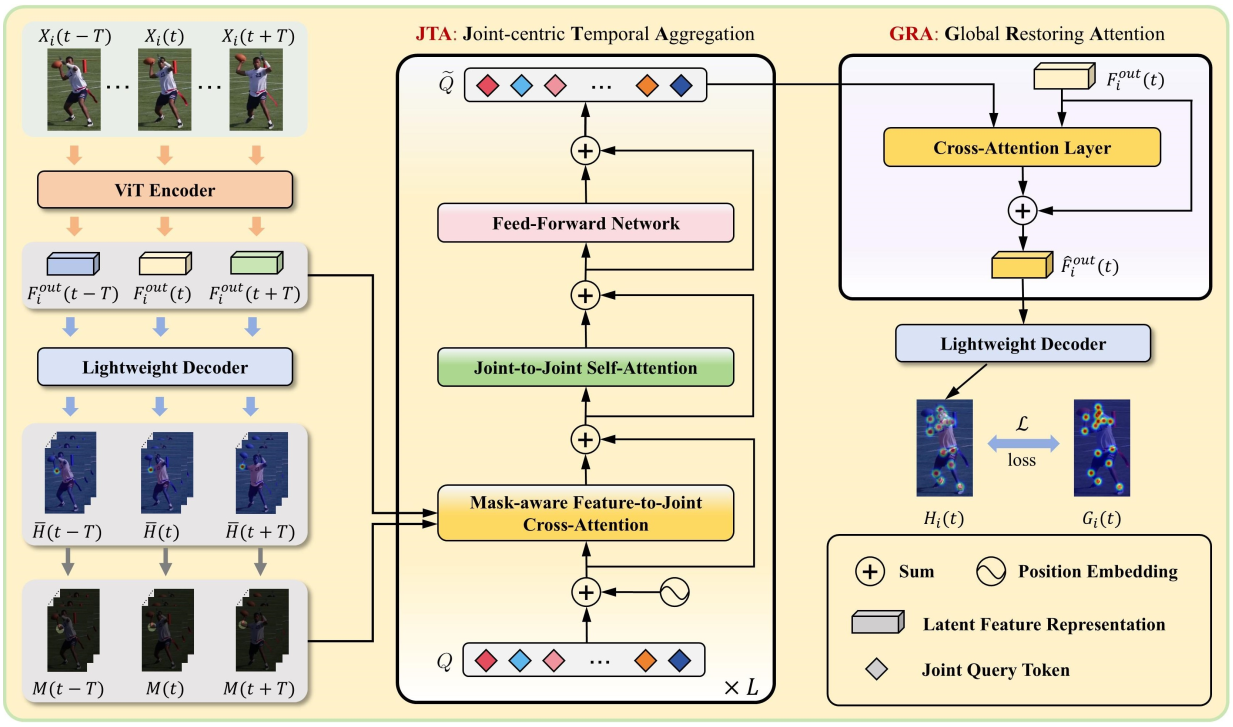
论文标题:Beyond Static Frames: Temporal Aggregate-and-Restore Vision Transformer for Human Pose Estimation
论文作者:方洪伟1,蔡佳航1,王勋1,杨文武1
完成单位:1. 浙江工商大学
论文简介:Vision Transformers(ViTs)由于其强大的全局建模能力,最近在2D人体姿态估计方面取得了最先进的性能。然而,现有的基于ViT的姿态估计器是为静态图像设计的,并独立处理每一帧,从而忽略了视频序列中存在的时间相关性。这种限制通常会导致预测不稳定,尤其是在涉及运动模糊、遮挡或散焦等的挑战性场景中。
针对上述问题,本文提出了一种新颖的时序聚合和恢复视觉Transformer网络:TAR-ViTPose(Temporal Aggregate-and-Restore Vision Transformer)。TAR-ViTPose面向视频二维人体姿态估计,通过以即插即用的方式聚合跨帧的时间线索来增强静态ViT表示,从而实现更稳健、更准确的姿态估计。为了有效地聚合跨帧时间对齐的特定关节特征,TAR-ViTPose引入了一种以关节为中心的时间聚合模块JTA,它为每个关节分配一个可学习的查询Token,以有选择地关注相邻帧中的相应区域。此外,还设计了一种全局恢复注意力模块GRA,将聚合的关节级时序特征恢复到当前帧的Token序列中,以丰富其姿态特征表示,同时完全保留全局上下文以实现精准的关键点定位。
大量实验表明,相比于单帧基线ViTPose,TAR-ViTPose显著提升了二维人体姿态估计的精度,在PoseTrack2017基准测试中实现了+2.3mAP的明显增益。此外,在多个公开基准数据集上,该方法均明显优于现有的最先进视频二维人体姿态估计方法,同时还在实际应用中实现了运行帧率的显著提升。项目代码即将开源:https://github.com/zgspose
CVPR会议介绍:
CVPR (Computer Vision and Pattern Recognition),即IEEE国际计算机视觉与模式识别会议,是计算机视觉领域世界三大顶级会议之一(与ICCV、ECCV并列),也是中国计算机学会(CCF)推荐的A类会议。自1983年创办以来,CVPR每年吸引全球数众多顶尖学者与工业界研究者参与,对创新性与实验完备性要求极高,是衡量视觉研究前沿水平的核心标杆。