
近日,我院王勋教授团队2篇论文被中国计算机学会(CCF)推荐的A类国际多媒体学术会议ACM International Conference on Multimedia(简称ACM MM)2022接收。ACM MM由国际计算机协会(ACM)在1993年发起,是多媒体处理、分析与计算领域具有影响力的国际会议。ACM MM 2022共收到 2473份论文有效投稿,其中接收690篇论文,录用率约为27.9%。会议将于2022年10月10日在葡萄牙首都里斯本举行。
Partially Relevant Video Retrieval
部分相关下的视频检索
董建锋1,陈先客1,章敏松1,杨勋2,陈书界1,李锡荣3、王勋1
1浙江工商大学
2中国科学技术大学
3中国人民大学
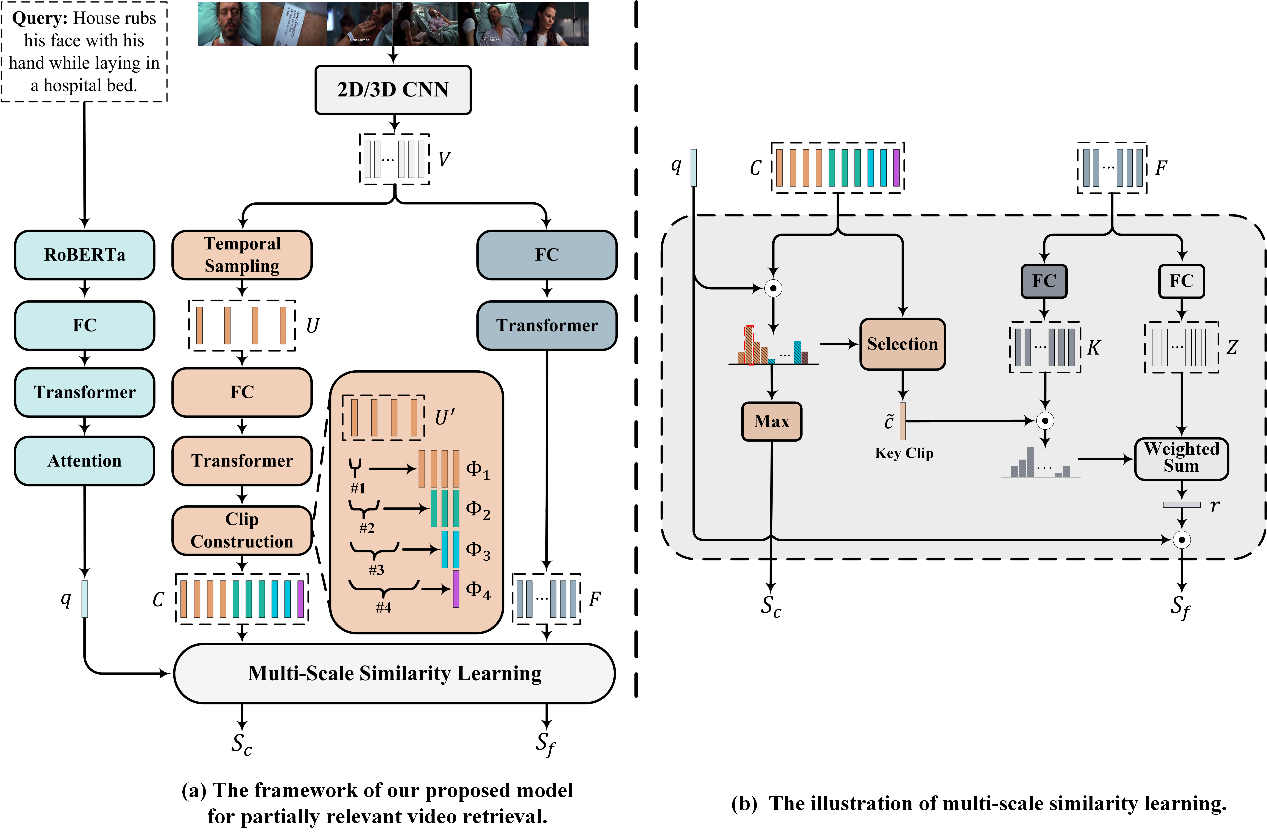
MS-SL 模型图
当前的文本到视频检索(T2VR)方法大多是在面向视频描述生成任务的数据集(如MSVD、MSR-VTT和VATEX)上训练和测试的。这些数据集存在共同的关键特性,即其包含的视频均以较短的持续时间进行预剪辑,同时提供的对应文本能充分描述视频内容的要点。因此,在此类数据集中所给出的文本-视频对呈完全相关的关系。然而在现实的视频检索场景中,由于查询文本是未知的,待检索的目标视频可能不包含足够的内容来完全满足查询文本。这表明现阶段在视频检索任务领域所训练的传统模型可能不适用于现实。为了弥补这一缺陷,我们在本文中提出了一种新的T2VR子任务——部分相关下的视频检索(Partially Relevant Video Retrieval, PRVR)。若一个未经剪辑的长视频中存在某一片段与给出的查询文本相关,则认为该长视频与给出的查询文本呈部分相关的关系。PRVR任务旨在从大量未剪辑的长视频中检索出与查询文本部分相关的对应视频,由于查询文本在对应长视频的相关时刻位置和持续时间都是未知的,所以PRVR任务相较于传统的T2VR任务更具挑战性。
由于PRVR任务和多示例学习存在着高度关联性,所以我们设计了多尺度多示例学习的方法来解决该任务。方法中视频被表示为多个片段尺度和帧尺度的特征,多尺度的特征表示有助于处理长视频与对应文本不同长度的相关片段。此外,基于多尺度的视频表示,我们提出了多尺度相似度学习(Multi Scale Similarity learning, MS-SL)网络。MS-SL网络包括片段尺度和帧尺度的相似度学习分支,它们以从粗到细的方式共同学习视频表示,并且上述两个分支存在交互。片段尺度相似度学习分支将检测出最有可能与查询文本相关的关键视频片段,计算其与查询文本间的相似度作为片段尺度相似度。接着以该片段为向导,在帧尺度相似度学习分支中衡量各帧的重要性,对各帧的特征表示进行加权和后与查询文本计算相似度作为帧尺度相似度。最后,将片段尺度相似度和帧尺度相似度联合用于衡量最终的视频-文本相似度。下图的性能比较能够表明,我们提出的模型相较于传统视频检索模型能够更好地解决PRVR任务。
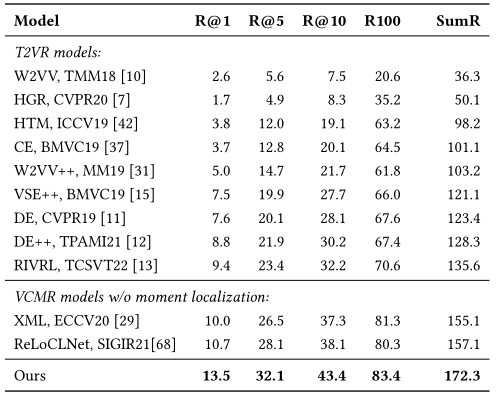
与传统T2VR模型与VCMR模型在TVR数据集上性能的比较
同时我们定义了片段时长/视频时长比(M/V)这一概念,它以通过查询文本所对应的正确片段持续时间除以整个视频的持续时间来衡量。M/V越小,表示对应视频与查询文本相关的内容越少,反之则越多。此外, M/V越小,查询文本与其对应视频的相关性越低,而M/V越大,相关性越高。根据M/V,查询文本可以被分类为不同的组,以此对不同模型如何响应不同类型的查询文本进行深入分析。我们在TVR数据集上将10895个测试查询文本根据其M/V分为六组。
我们的模型在所有分组中中始终表现最好。从左到右观察下图,12个比较模型的平均性能随着M/V的增加而增加。最低M/V组的表现最差,而最高M/V组的表现最好。这表明,传统的视频检索模型能够更好地应对与相应视频具有更大相关性的查询。相比之下,我们在所有M/V组中取得的成绩更为平衡。这一结果表明,我们提出的模型对视频中的无关内容不太敏感。
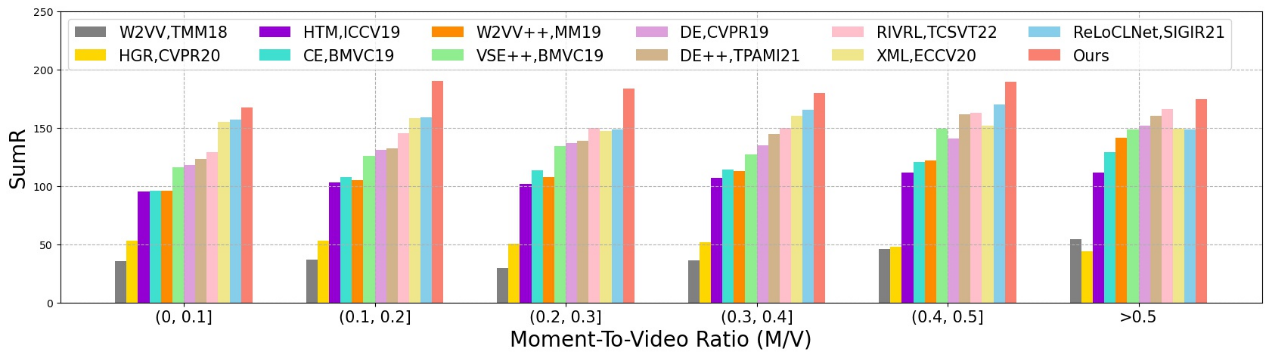
M/V 分组实验结果
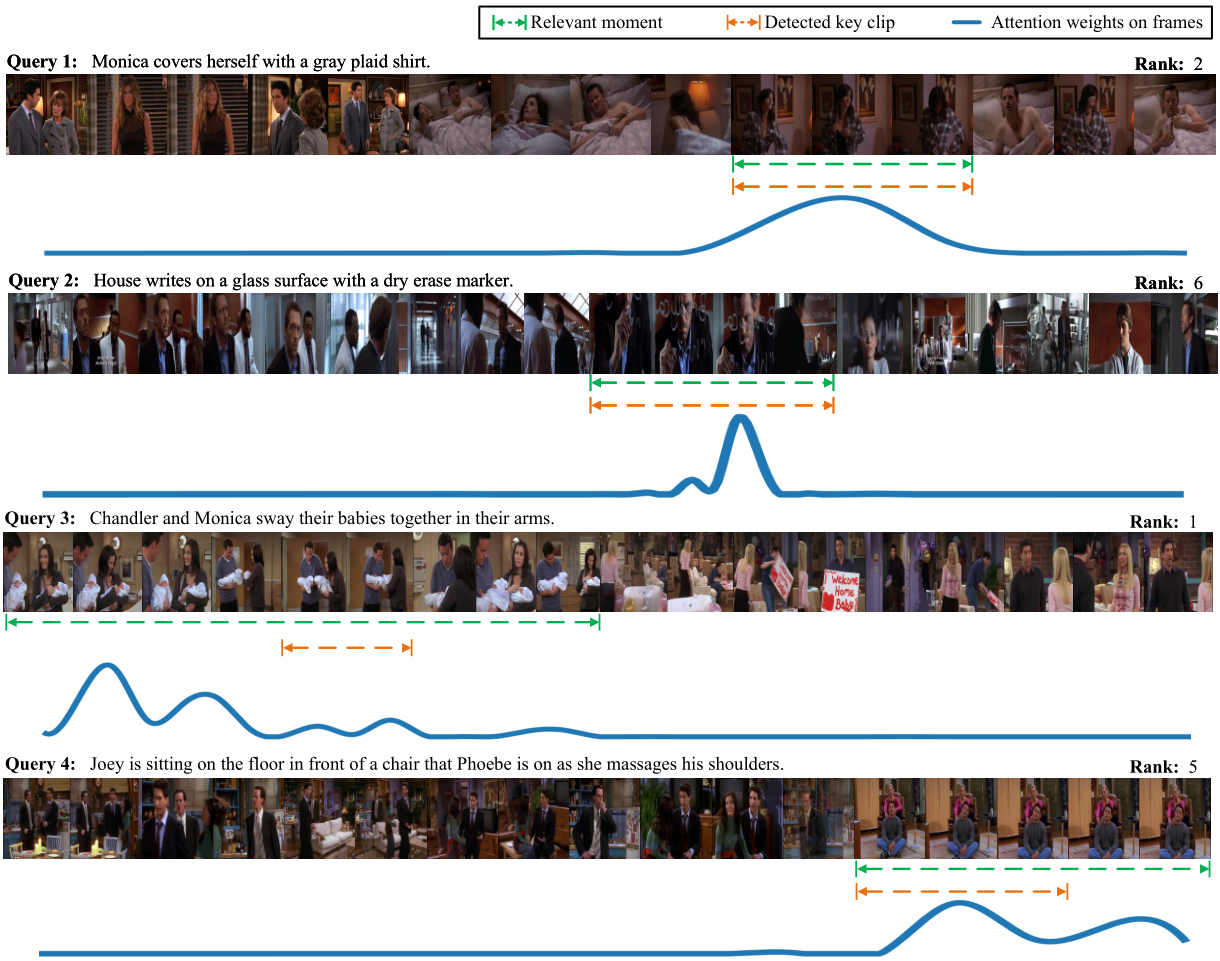
下图我们给出了一些模型检索过程中的可视化实例,分别给出了查询文本在其对应视频中由模型检测出的关键片段范围与关键片段和所有视频帧之间的相似度曲线。在前两个查询实例中,模型检测出的关键片段与正确相关片段完全重合。在后两个查询实例中,检测出的关键片段虽然和正确相关片段只有小部分重合,但是关键片段与正确相关片段所包含的帧均具有较高相似度。这表明帧尺度相似度学习分支可以帮助片段尺度相似度学习分支在一定程度上补齐缺失信息,进一步反映了模型设计双分支相似度学习模块的合理性。
Cross-Lingual Cross-Modal Retrieval with Noise-Robust Learning
噪音鲁棒学习的跨语言跨模态检索
王雅冰,董建锋,梁天祥,章敏松,蔡蕊,王勋
浙江工商大学
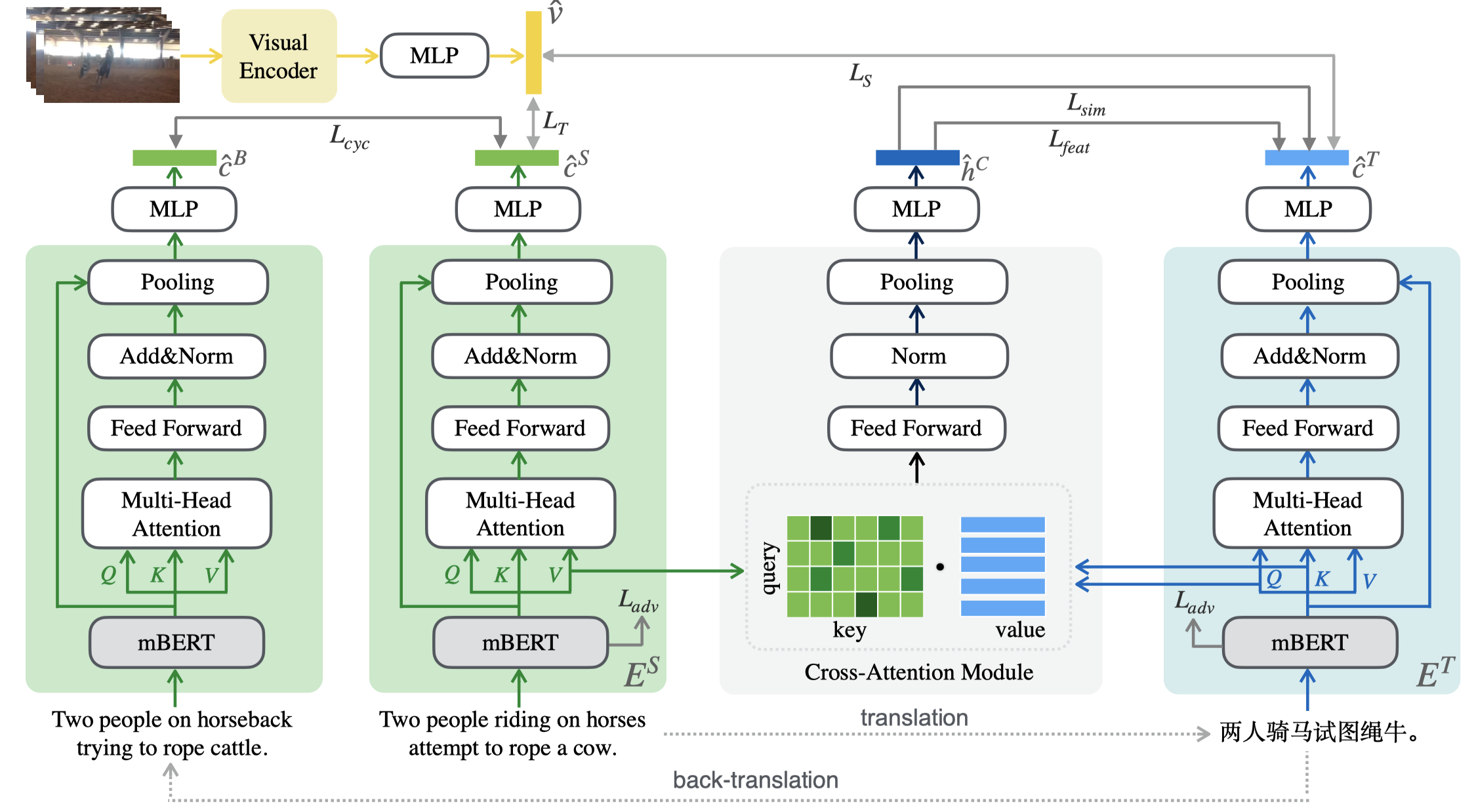
随着多媒体技术的发展,跨模态检索领域的研究受到了越来越多研究者的重视,但由于缺乏人工标注的低资源视觉语言数据集,因此该领域在针对于低资源语言方面的研究较少,并且面临着巨大的挑战。为此,我们通过使用机器翻译来构造关于低资源语言的伪平行句子对来缓解人工标注的困难。然而,机器翻译并不是完美的,它在翻译过程中通常会引入大量的噪声,导致模型对噪声数据过拟合,并因此损害检索性能。针对这一问题,我们提出了一种噪声鲁棒的跨语言跨模态检索方法,该方法利用cross-attention模块来生成软伪目标,从基于相似度和特征的两个视角为目标语言的学习提供直接的监督。受无监督机器翻译的启发,我们还提出利用回译技术来最小化原始句子和回译句子之间的语义差异以提升文本编码器的噪声鲁棒能力。此外,我们通过对MSR-VTT的英语测试集进行了人工中文翻译,构造了一个新的多语言视频文本检索数据集MSR-VTT-CN。我们在三个多语言视频文本检索和图像文本检索数据集上进行了大量的实验,结果表明我们的方法在不使用额外的人工标注数据的情况下显著提高了整体性能。
如下表所示,我们将SOTA模型分为了两组,第一组为使用ResNet-152作为图像backbone的模型,第二组为在大规模视觉语言语料库中进行预训练的模型。结果表明,我们的模型取得了显著的性能优势。此外,我们将图像编码器从ResNet-152换成更强的预训练编码器CLIP,我们的模型在该数据集的所有语言上均得到了显著的性能提升,并且显著优于其他预训练模型,该结果证明了我们的模型可以兼容更强的视觉编码器。
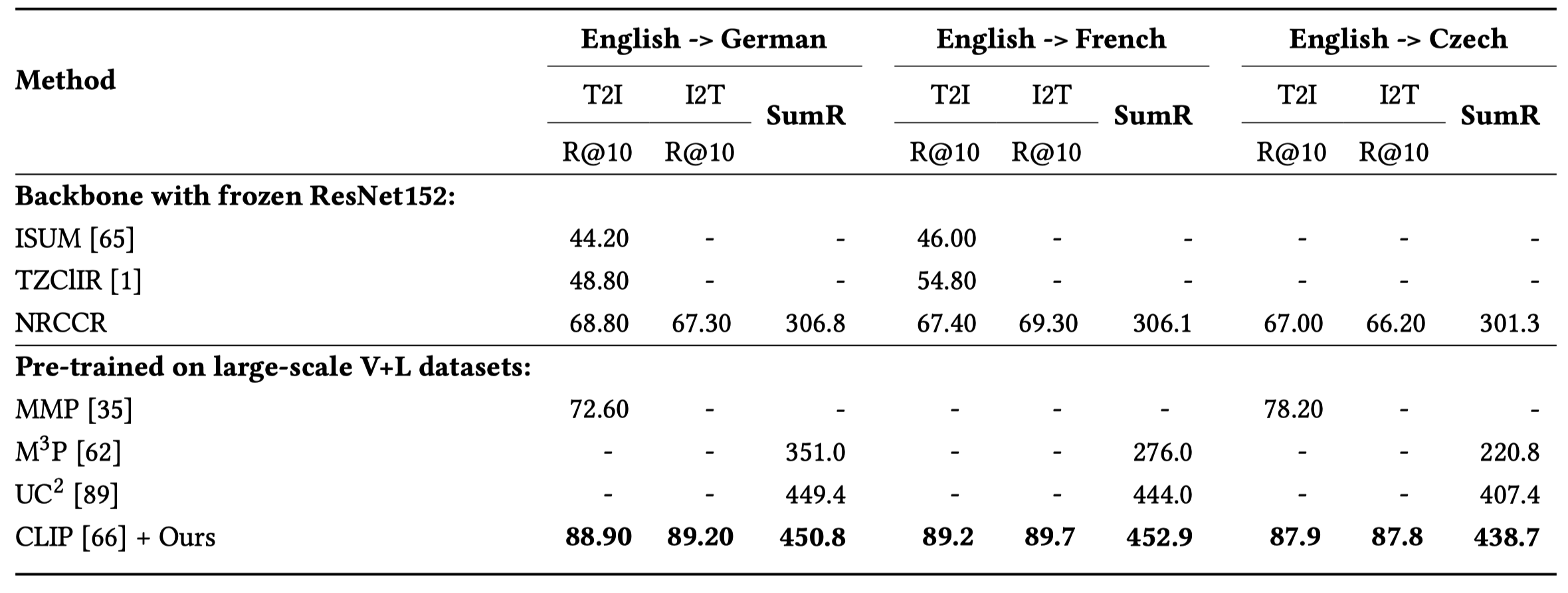
与前沿方法的性能比较
为了进一步证明我们的模型对于翻译噪声的鲁棒性,我们通过增加翻译次数来增加噪声程度。如下图所示,“GoogleTrans”表示在一次翻译后的数据上进行训练,”GoogleTrans++”表示使用在经过三次翻译后的数据上进行训练,通过多次翻译,Basic Model的性能急剧下降,而我们的模型相比之下更加的稳定,这充分表明了我们所提出的噪声鲁棒特征学习方法的有效性。
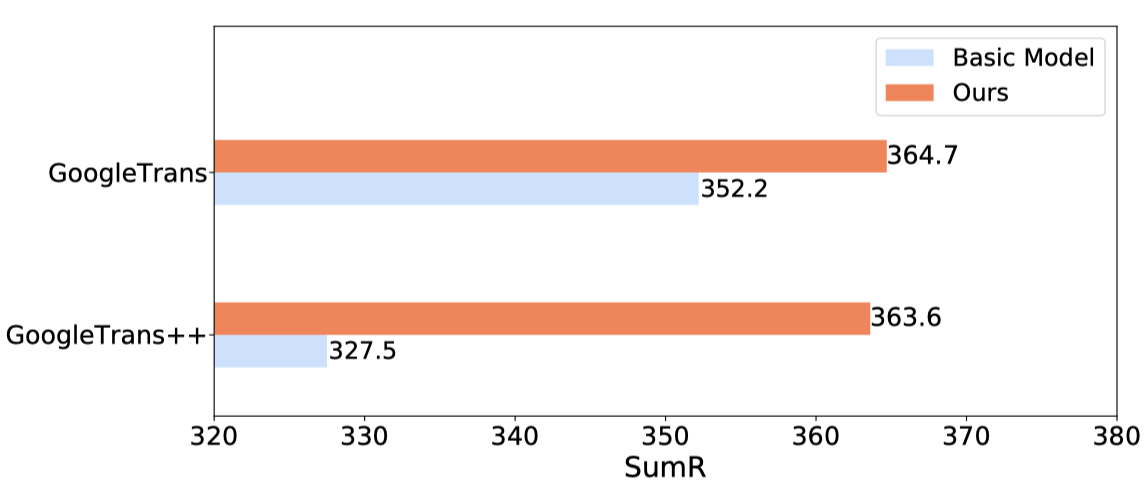
与Basic model的噪声鲁棒性实验
我们随机采样了20个样本,每个样本包含一个视频特征,十个中文句子特征和它所对应的英文翻译句子特征。如下图所示,与Basic Model相比,我们的模型的类内距离更加紧凑,这表明我们的模型已经学习到了语言无关特征表示并实现了更好的跨语言跨模态对齐。此外,通过机器翻译得到的英语句子是有噪声的,但在图(b)中,英语句子特征仍然与中文句子特征紧密的聚集在一起,这一结果在一定程度上说明了我们的方法能够从带有噪声的英语句子中提取到原始的语义信息,其原因可能是我们的方法经过了循环语义一致性学习的优化。
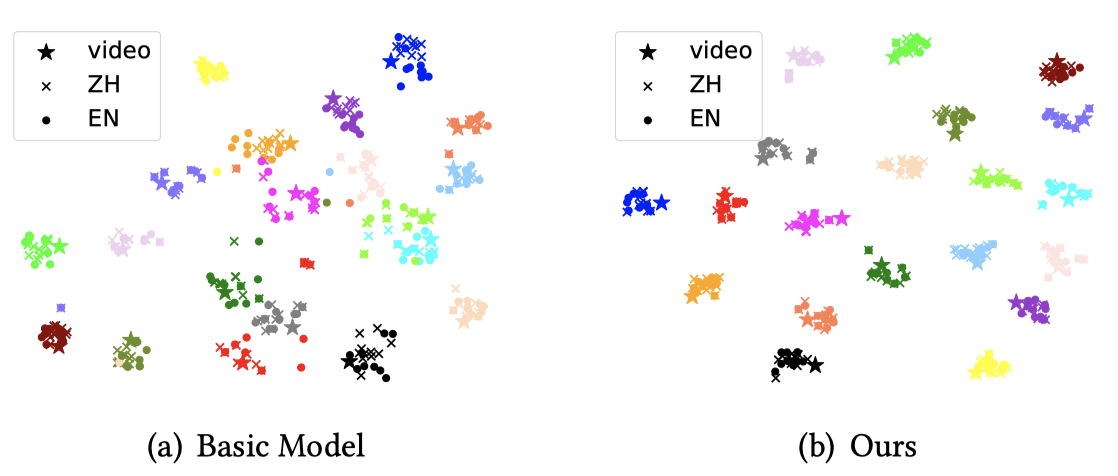
与Basic model的t-SNE可视化结果对比